
MaxGuide全力出动 | 第一集:积累会员积分‘Lock Tree’
2017-08-11
为了分析储存在Hadoop Distributed File System(HDFS)中的数据,我们会用到各式各样的软件或者语言。这其中,最具代表的就是HIVE, Pig, Spark, Python, Scala和R了。
使用HIVE, Pig可以对大容量数据济宁快速简单的整理,Spark则可以帮助大家使用例如machine learning方式的in-memory分析。
而R就是比之前所有的统计分析巩固都要容易上手的一个不可或缺的工具。
在这个章节里,我们在众多统计分析工具中,只选择R进行讲述。为了分析在大数据eco系统构成后锁累积的数据,需要在特定的服务器上安装R。但是即便是安装好了R,也并非可以直接像在本地分析数据一样进行操作。
首先,从系统角度而言,R需要能够链接到Hadoop。当系统设置结束以后需要在R console(或者是R Studio)中使用函数和package去连接Hadoop。现在,我们来给各位逐步讲解在系统层面将R和Hadoop链接之后如何使用Package和函数来操作Hadoop内部的大数据。
1.1. 大数据eco系统环境参数设置
为了在大数据eco系统中使用R,需要设置环境参数。关于一些基本设置参数的信息,我为大家列了一个表格,请各位参考。
Sys.setenv() : 环境参数设定函数
| 命令语句 | 执行内容 | 备注 |
| Sys.setenv (JAVA_HOME=”/data/user/jdk1.7.0_80″) |
指定设置在HDFS中的JAVA路径 |
路径和版本信息会根据Java和Hadoop设置人员的 不同而出现变更。 此次, |
| Sys.setenv (HADOOP_CMD=”/usr/lib/hadoop/bin/hadoop”) | 指定在R中执行操作的HDFS路径 | |
| Sys.setenv (HADOOP_STREAMING=”/usr/lib/hadoop-mapreduce/hadoop-streaming.jar”) | 指定为了实时分析的Streaming路径 | |
| Sys.setenv(SPARK_HOME=”/usr/lib/spark”) | 指定为了执行SparkR的Spark路径 |
分析人员如果知道了这些想要分析的数据所积累的大数据环境的各项参数,就可以按照下面的顺序去将R和大数据系统进行连接。
下面我们采用了SSH方式作为例子并利用Putty Client为大家讲解。
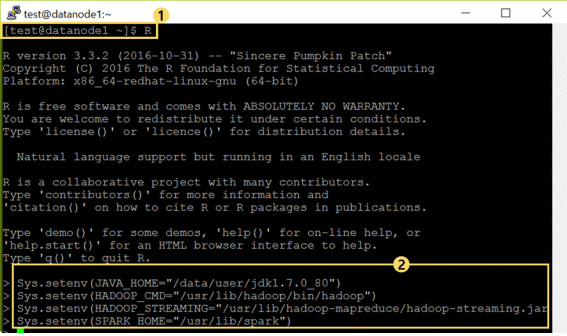
① : 连接Linux账户以后输入R来执行R console
② : 在R console画面中设定Hadoop系统的环境参数
{rhdfs} : rhdfs是一个package使得HDFS和R可以进行连接,因此在cran中并没有提供。需要用户在GitHub中去直接下载并安装在R client会执行的node中。
关于package的下载和安装可以在下面的GitHub页面进行确认,在R中使用 install.packages()函数来进行设置。
https://github.com/RevolutionAnalytics/RHadoop/wiki
hdfs.init() : 使用将Hadoop构成文件位置进行特定化的参数的{rhdfs}package初始函数
如果※ hdfs.init()函数可以正常运行的话,则可以在R里面启动HDFS并进行呼唤数据/数据储存等和数据文件相关联的操作。
hdfs.ls(“直接路径”):可以查看HDFS的特定直接路径的信息。
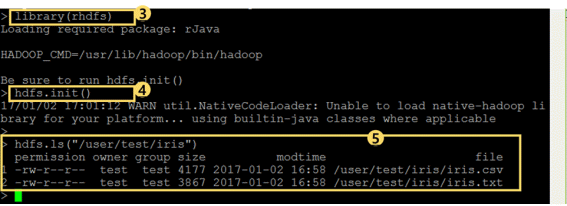
③ 使用library(rhdfs)或者require(rhdfs)加载{rhdfs}package
④ 使用hdfs.init()初始化; warning()告警信息可以忽略
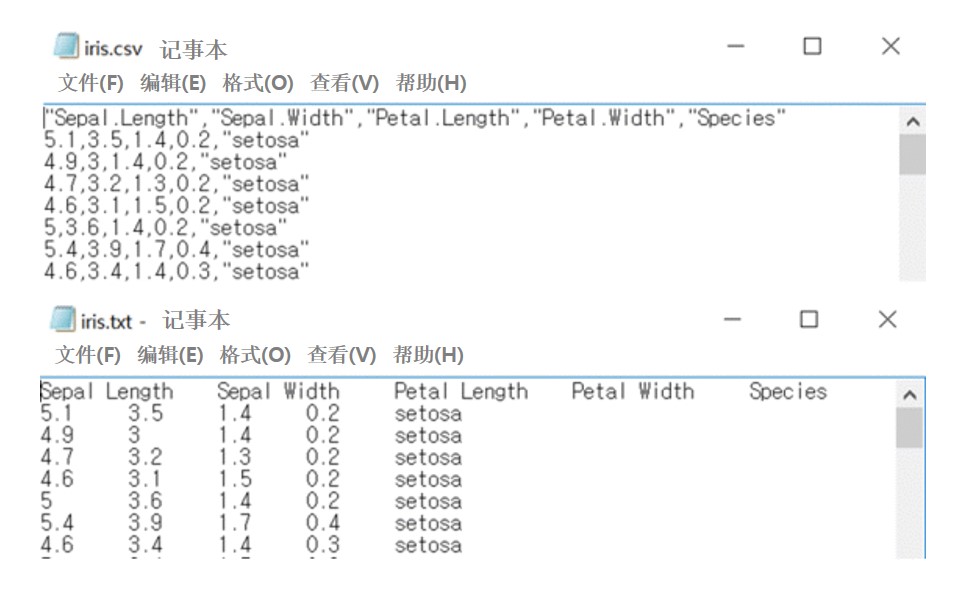
⑤ 使用hdfs.ls()函数能够查看在/user/test/iris路径下存在‘iris.csv’和‘iris.txt’。还要留意iris.csv文件中数据用逗号(,)进行区分而 iris.txt文件的数据则用Tap(\t )进行分类。
1.2. 读取数据
hdfs.cat(“文件路径”):将HDFS上的文件以text行为单位进行读取。
※ 在HDFS中存在着很多像hdfs.line.reader(), hdfs.read.text.file()一样读取数据的函数,在这里我们使用 hdfs.cat()函数来进行数据的读取。
1.2.1. 读取CSV文件
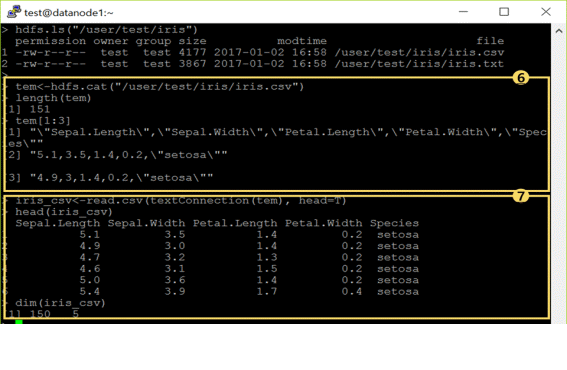
⑥ – 使用hdfs.cat()函数读取 “/user/test/iris”路径下的 iris.csv文件。
- 使用length()函数可以确认出读取了151个line
– 使用 tem[1:3]命令可以查看以hdfs.cat()形式出现的和客体tem打印效果一样形式的通过包含参数名的text数据形式所读取的内容。
⑦ – 因为客体tem已经是通过逗号(,)分类的text line形式,使用 read.csv()函数可以读取上述tem。 此时通过 textConnection()函数将text形态的tem插入(input)到函数 read.csv()之中。因为第一行需要使用栏(参数)名,所以需要使用 read.csv(… , head=T)选项。
– 能够确认的结果是,在iris_csv的dimension是150行5列,第一行由于使用了栏名的缘故,比使用 length()的时候要少了一行。
1.2.2. 读取tap分离 text文件
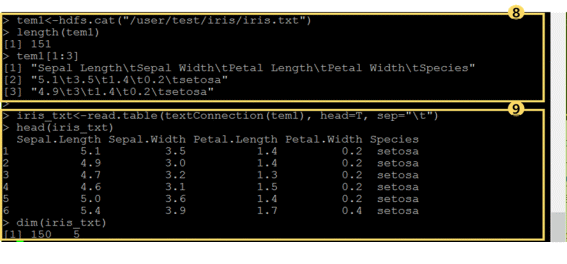
⑧ -利用 hdfs.cat()函数来读取“/user/test/iris”路径下的 iris.txt文件。
- 使用length()函数可以确认出读取了151个line
- 使用 tem[1:3]命令可以查看以cat()形式出现的和客体tem1打印效果一样形式的通过包含参数名的text数据形式所读取的内容。
⑨ – 客体tem1已经是tap(\t)分类的text line形态,利用 read.table()函数可以读取上述tem1。此时,利用 textConnection()函数可以将text形态的tem1插入(input)至函数 read.table()中。并且第一行通过栏(参数)名来指定使用和分类(\t)选项。 read.table(… , head=T, sep=”\t”)
– 确认结果可以发现iris_txt的dimension上有150行5列,因为第一行使用了栏名的关于,比起使用 length()的时候要少1行。
1.3 数据储存
hdfs.put(data file, “HDFS 路径”) : hdfs.put()函数会从本地文件系统里复制/移动用户指定的HDFS上的文件或进行文件名变更的函数。
※一般来说在本地文件系统特定路径中将文件储存之后,使用 hdfs.put()函数可以将文件复制到HDFS中。
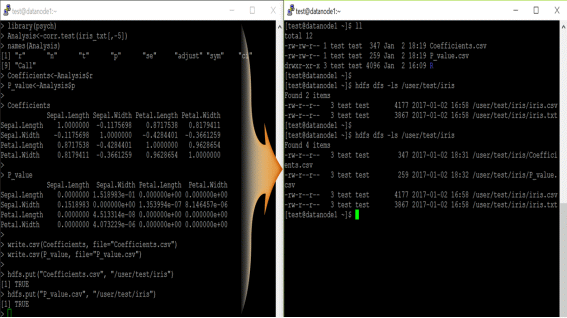
例如,利用上述读取的iris数据,可以执行‘Sepal Length’, ‘Sepal Width’, Petal Length’, Petal Width’的相关分析,现在我们就把分析结果(斯皮尔曼相关系数,显著性概率)通过csv文件储存在HDFS的‘/user/test/iris’路径中。
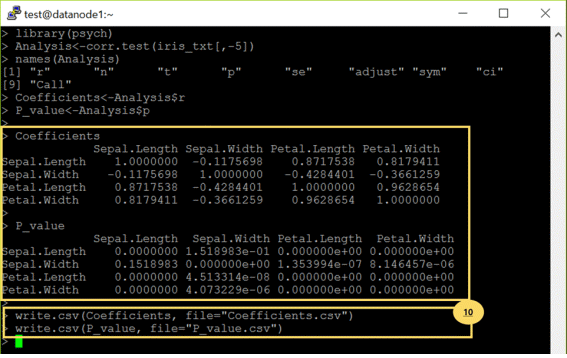
⑩将相关分析执行后的斯皮尔曼相关系数(Coefficients)和显著性概率(P_value)通过 write.csv()函数分别生成叫做 Coefficients.csv 和 P_value.csv的文件并储存在本地。
※相关分析的部分请参考<交叉分析和相关分析>
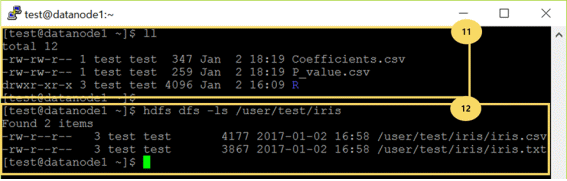
⑪可以确认 Coefficients.csv和P_value.csv已经储存在本地。
⑫可以确认在HDFS中的‘/user/test/iris’指定路径中只存在着之前读取的 iris.csv和iris.txt文件。

利用 hdfs.put()函数可以将储存在本地的各种文件复制到HDFS的 “/user/test/iris”路径中。
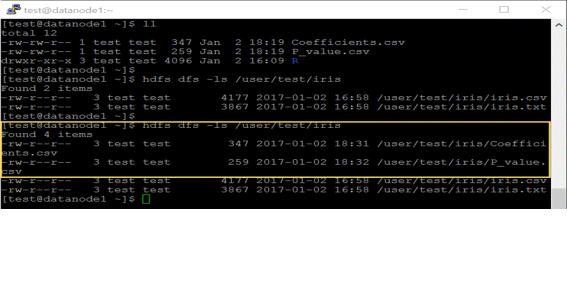
可以确认本地的文件已经被成功复制到HDFS路径。
<参考> 生成iris.csv, iris.txt
在R console窗口数据下列命令来生成。
| iris.csv | write.csv(iris, “储存路径/iris.csv”, row.names=F) |
| iris.txt | write.table(iris, “储存路径/iris.txt”, row.names=F, sep=”\t”) |
Leave a Reply
Be the First to Comment!